회사에서 사내 스터디를 진행하고 있는데, 나는 이번에 AI Engineering 이라는 책을 완벽히! 읽어보고자 한다
기록하는 이유는, 내가 다시 보려고!
https://www.oreilly.com/library/view/ai-engineering/9781098166298/
AI Engineering
Recent breakthroughs in AI have not only increased demand for AI products, they've also lowered the barriers to entry for those who want to build AI products. The model-as-a-service approach … - Selection from AI Engineering [Book]
www.oreilly.com
그럼 이제부터 시이이작
Chapter1. Introduction to Building AI Applications with Foundation Models
- 엄청난 규모로 운영, 훈련시키기 위한 데이터가 부족해질 위험도 있음
- 방대한 데이터, 컴퓨팅 자원, 전문적인 인력 필요
Model as a Service서비스로서의 모델 개념 등장- 소수의 조직에서 개발한 모델을 다른 사람들이 서비스 형태로 활용할 수 있도록 제공하는 것
The Rise of AI Engineering
From Language Models to Large Language Models
언어 모델은 현재의 규모로 성장할 수 있었던 것은 자기 지도 학습 덕분
✅ 자기 지도 학습
- 레이블이 없는 데이터로부터 학습하는 인공지능 기법
- 레이블이나 주석이 필요하지 않은 대신, 데이터 자체에서 학습 과제를 생성함
- example) 이미지에서 일부를 가리고 모델이 가려진 부분을 에측하기 하는 것이 자기지도 학습의 한 예시
- 모델이 데이터의 내재된 구조와 패턴을 이해하도록 도움
- 지도학습과 비지도학습의 중간
- Unsupervised-learning 과 동일한데, 데이터로부터 supervision signal을 만든 후에 예측하도록 학습하도록 → 데이터를 변경, 데이터를 가리기 → 온전한 데이터만 있으면 만들 수 있음
- 자기지도 학습의 목표
- 많은 데이터로부터 지식을 학습하고 다양한 어플리케이션에 적용하는 것이 자기지도 학습의 목표
- 레이블이 없을 때 → unsupervised learning → 잘 될 수가 없음
- clustering → 적용해보면 → 잘 되는 부분, 잘 안되는 부분 둘다 있음
- 자기지도 학습의 사용과 예시
- NLP → large scailing model
- BERT, GPT-3
- image, video, speech, text
- Pretext Tasks
- 데이터 스스로 레이블을 만들고, supervised learning 적용
- augo-regressive LM
- 전단어가 주어졌을 때 다음 단어 예측
- 온전한 텍스트만 있으면 .
- masked LM
- BERT
- 랜덤으로 단어를 MASK 로 바꿈,
- Next sentence prediction
- relative positioning
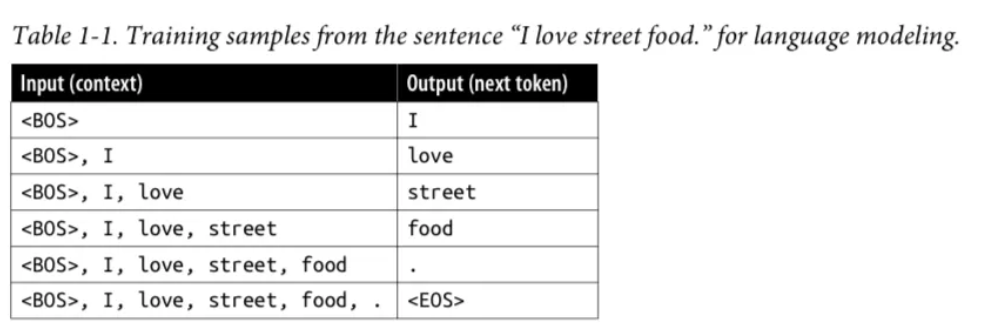
- vision 쪽, bert 이전
- 기본 아이디어: 랜덤 패치 하나 정함 → 주변 8개, 랜덤 노이즈, 크기도 변경함 → 패치를 2개를 두고 8개중 어딜까요?!
- contrasive learning
- 페어를 제공하고, 샘플간의 비교를 통해 학습을 하는 것
- 거리의 constant 거리보다 작아야한다 요런 아이디어
- 같은 이미지에서 나온 패치는 같게 예측할 수 있도록
- 다른 이미지에서 나온 것은 다르다고 예측할 수 있도록
- contrasive learning
- NLP → large scailing model
Language Model
한개 또는 그이상의 언어에 대한 통계정 정보를 인코딩하는 시스템
- 언어 모델은 크게 두 가지로 나뉨
- 마스킹 언어 모델 (Masked Language Model, MLM)
양방향 학습(앞뒤 문맥 활용) → 문장 전체의 이해에 유리- 문장 중 일부를 가린 후, 앞뒤 문맥을 활용하여 누락된 단어(토큰)을 예측하도록 훈련
- 예) my favorite __ is blue ⇒ color 예측
- 감성분석, 텍스트 분류, non-generative 작업에 사용됨
- 자가회귀 언어 모델 (Autogressive Language Model, ARLM)
단방향 학습(앞쪽 문맥만 활용) → 자연스러운 텍스트 생성에 유리- 앞선 토큰들만 활용하여 다음 토큰을 예측함
- 예) my favorite color is ⇒ 다음 단어를 순차적으로 예측
- 텍스트 생성, GPT
- 마스킹 언어 모델 (Masked Language Model, MLM)
Generative AI
- 언어 모델은 주어진 입력을 바탕으로 텍스트를 완성하는 역할
- 확률 기반으로, 정답을 보장하지 않음
- 확률적 특성 떄문에 모델이 매우 유용하면서 때로는 예측 불가능한 출력을 생성할 가능성이 있음
- 한계점이 존재함
- 단순한 텍스트 완성 기능은 대화형 시스템과 다름
- AI모델이 대화 중 질문을 받았을 때 질문을 답변하는 대신 또다른 질문을 추가하는 방식으로 동작할 수 있음
⇒ 해결방법은 Post Training
- 대형 모델이 더 많은 데이터를 필요로 하는 이유
- 대형 모델이 학습할 수 있는 용량이 더 크기 때문에 최대 성능을 내기 위해서 더 많은 데이터를 필요로 함
Multimodal
- 여러 데이터 유형을 동시에 이해하고 생성할 수 있는 모델 ****
- 최근 AI 모델들은 이미지, 3D 데이터, 단백질 구조 등 다양한 데이터 유형을 학습할 수 있도록 확장됨
- GPT-4V, claude3과 같은 모델이 이미지와 텍스트를 동시에 이해할 수 있음
- 추가적인 모달리티를 LLM에 통합하는 것이 AI연구와 개발의 핵심 분야 중 하나라고 소개함
- Foundation models (기반 모델)
- 여러 모달리티를 하나의 모델에서 처리할 수 있도록
- LLM(large language model) + LMM(large multimodal model) 을 모두 포함하는 개념
- Super-NaturalInstructions Benchmark
- RAG, Fine-tuning,prompt engineering을 통해 원하는 방식으로 활용할 수 있도록 함
- Foundation Models의 활용이 AI 애플리케이션 개발 비용을 줄이고 출시 속도를 빠르게 만들어줌

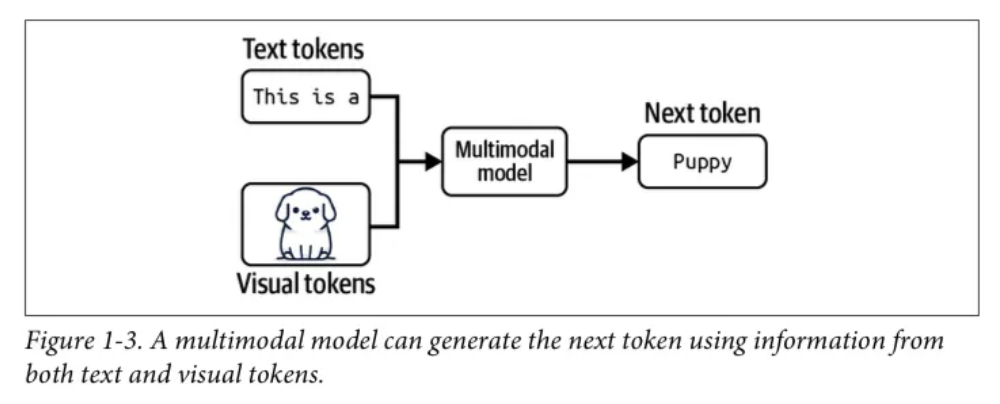
Generative Multimodal Model(생성형 다중 모달 모델) → LMM(Large Multimodal Model)
- 다중 모달 모델은 시각정보(강아지 이미지)도 활용해서 Puppy라는 다음 단어를 예측함
- 자기지도 학습의 다중 모달 모델 적용
- OpenAI는 CLIP모델(OpenAI, 2021) 에서 자연어 기반 감독(natural language supervision)을 활용해서 이미지-텍스트 모델을 훈련
- 특정 이미지 분류 작업에 맞춰 훈련된 것이 아니라 일반적인 이미지-텍스트 관계를 학습
- 새로운 이미지 분류 작업에도 추가 훈련 없이 일반화할 수 있음
- 임베딩 모델임 !!!
- 텍스트-이미지 의미 공간에 매핑하는 역할을 함
- 새로운 이미지를 생성하는 것이 아닌 주어진 이미지와 가장 잘 맞는 텍스트를 찾는 것이 주된 목적
- OpenAI는 CLIP모델(OpenAI, 2021) 에서 자연어 기반 감독(natural language supervision)을 활용해서 이미지-텍스트 모델을 훈련
Tokenization
토큰화: 텍스트를 토큰으로 분활하는 과정, 언어 모델의 기본 단위- 토큰은 모델에 따라 문자, 단어, 단어의 일부일 수 있음
- 어휘: 모델이 처리할 수 있는 모든 토큰의 집합
왜 토큰을 사용할까요 ?!
- 의미 있는 구성 요소로 분해 가능
- 문자 단위보다 토큰 단위가 더 의미 있는 단위로 문장을 분해할 수 있도록 도와줌
cooking⇒cook+ing
- 효율적인 모델 크기 유지
- 고유한 단어의 수보다 고유한 토큰의 수가 더 적기 때문에 모델의 어휘 크기를 줄일 수 있음
- 모델이 더 효율적으로 작동하도록 함
- 알 수 없는 단어 처리 가능
- 새로운 단어를 이해하는 데 도움이 됨
chatgpting⇒chatgpt+ing- 토큰은 단어보다 개수가 적지만, 개별 문자보다는 더 많은 의미를 보존할 수 있음
AI Engineering의 개념
- Foundation Model을 활용한 AI 애플리케이션 개발을 의미
- General-purpose AI capabilities
- Increased AI investments
- Low entrance barrier to building AI applications
'AI > TIL' 카테고리의 다른 글
| [AI] AI-Engineering chapter2 (0) | 2025.02.11 |
|---|